Key Benefits of a Data Fabric
Data fabrics provide an efficient, reliable data management system that increases the velocity and speed of analysis and decision making. With data fabrics, organizations can leverage all of their data across disparate systems – including on premise, hybrid cloud, and multi-cloud environments.
Data fabrics unify heterogeneous data sources with a single connected platform – making data insights easy to find, navigate, and use for all users.
Key Benefits Include:
- Cost Saving: Reduce operational effort and overhead
- Data Democratization: Effective data-driven decision-making
- Data Governance: Meet various internal and external governance needs
- Scalability: Ability to meet exponential data growth
- Agility: Navigate multi-cloud environments
- Data Integration: Need for a unified and comprehensive platform.
What is Data-as-a-Product and What Are the Benefits?
‘Data-as-a-Product’ presents a paradigm shift in how organizations manage data to make data democratization a reality. It improves data access and delivers data in a way that allows your organization’s users, at all skill levels, to get immediate value. They don’t need to be experts.

Easy to Find and Use
Well defined, meaningfully described, searchable, and sharable

Provides Real Value
Measure and manage effectiveness of data products

Easy to Build and Manage
Business-friendly way to build and manage data products without technical complexity
Data-as-a-Product
The concept has gained traction with the emergence of defined approaches like the data mesh, pioneered by Zhamak Dehghani of ThoughtWorks. The methodology was brought into place to address:
- Rapidly growing data volumes and use cases
- Need to enable quick access to datasets across a large organization
- Shortcomings of traditional data architecture – including those of data warehouses and data lakes
- Relieve administrative burden on central data teams, while empowering business units with easy access to data insights
Data-as-a-Product achieves these objectives by creating a customer-centric product mindset around organizational data.
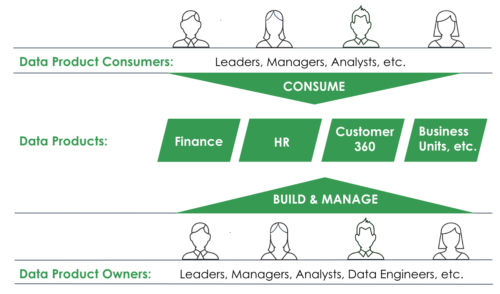
Benefits of Data Products:
Easy to Build and Find
Be able to build and engage with data products using natural language without needing to know SQL.
Domain Specific
Data products can be defined and made to be searched by a specific department. For example, data products can be configured for sales, finance, marketing, etc.
Easy to Consume
Data products deliver actionable insights derived from complex data in a user-friendly and accessible format, enabling straightforward interpretation by any users or/and application.
Easy and Secure Organization-wide Access
Data products streamline user access processes with governance that supports the organization without slowing it.
Easy to Measure and Monitor
Data products are trackable and enable organizations to continually monitor usage and gauge effectiveness, collecting such metrics as the number of queries a data product receives, and the number of answers it yields.
The Power of Data Fabrics vs. the former Best-of-Breed Approach
By removing the complexity of underlying data models, schemas, and structure, data can be provisioned in near real-time. Using a data fabric, data and analytics leaders can provision data in the right shape, at the right time, to the right consumer.
Data fabric is an open architecture that utilizes the best-of-breed approach that provides flexibility to the users. The idea of having a few best-of-breed systems to deliver deep specialization for a specific use case is undoubtedly important. But, when the specialization turns into sub-specialization the number of products (from different vendors) in each category mushroom uncontrollably. The result of which is that this becomes nothing more than a fragmented data stack. In other words, we are back to square one with a modern version of the Hadoop zoo sprawl.
The reality is that at some point the cost and overhead of integrating multiple products reaches a tipping point and no longer delivers an adequate ROI on the data infrastructure investments. In addition, there is a lack of interoperability across the tools. For instance, each may do its own data discovery and, due to the lack of a common metadata standard, is unable to communicate with other tools. Vendors have solved this problem by developing an arsenal of connectors. While looking good on paper, these connectors have to be manually developed and maintained which further leads to higher integration costs and time to value.
As a result, the ideal customer for a data fabric is the business user responsible for quickly generating value. The non-technical user of a data fabric is responsible for building data products. This is opposed to a data engineer, the primary user of a best-of-breed approach.
AI-Native Data Fabrics – a More Powerful Approach
Data platforms today are largely a “system of record” stack, which brings together data from a variety of enterprise databases and applications in a common repository. Their challenges include data silos, poor data quality and duplication, and fragmentation of stack components. The primary use case today for this stack is reporting and analytics, and in very few cases data-driven automation. What could be better than infusing intelligence within the data platform to accelerate the adoption of AI data products and applications throughout the enterprise? High-quality, curated data and metadata are key to success with generative AI initiatives.
Self-service to Data Products in Real-time
AI-native data fabrics have AI built within the engines and were assembled before generative AI tools like ChatGPT became widely available. With AI-native data fabrics, foundation models can be leveraged out-of-the-box without refactoring code. This allows data products to be refined and delivered leveraging GenAI. Overall, it provides a more efficient and sophisticated way to provide self-service to data products in real time.